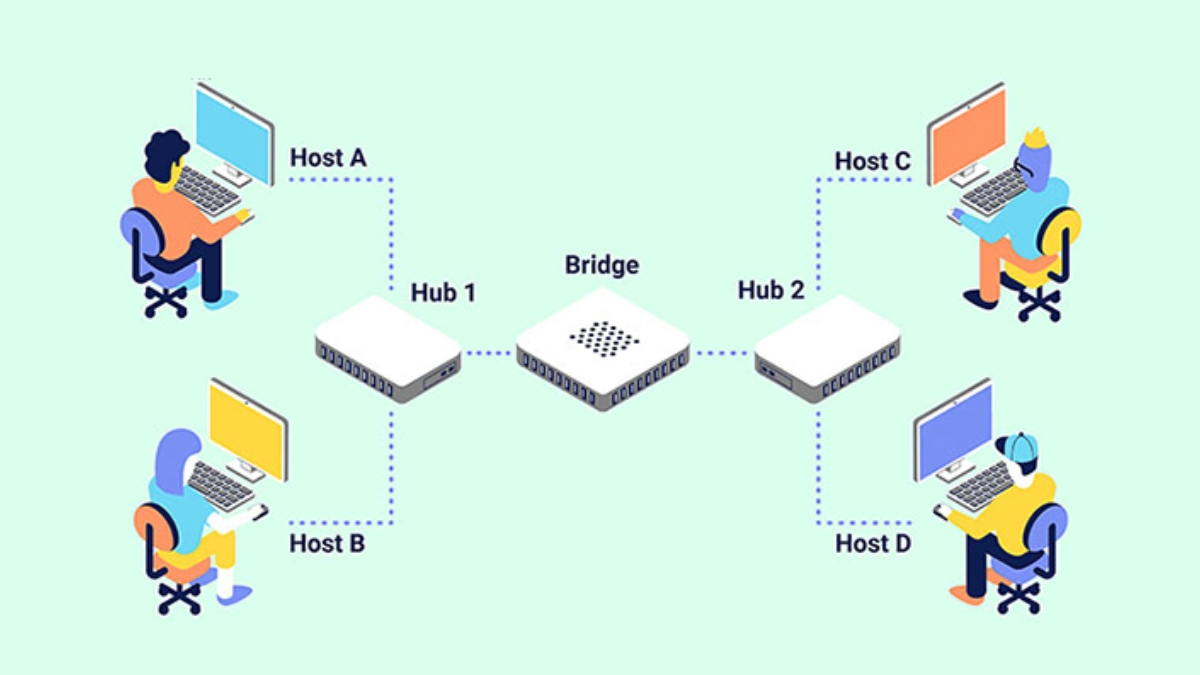
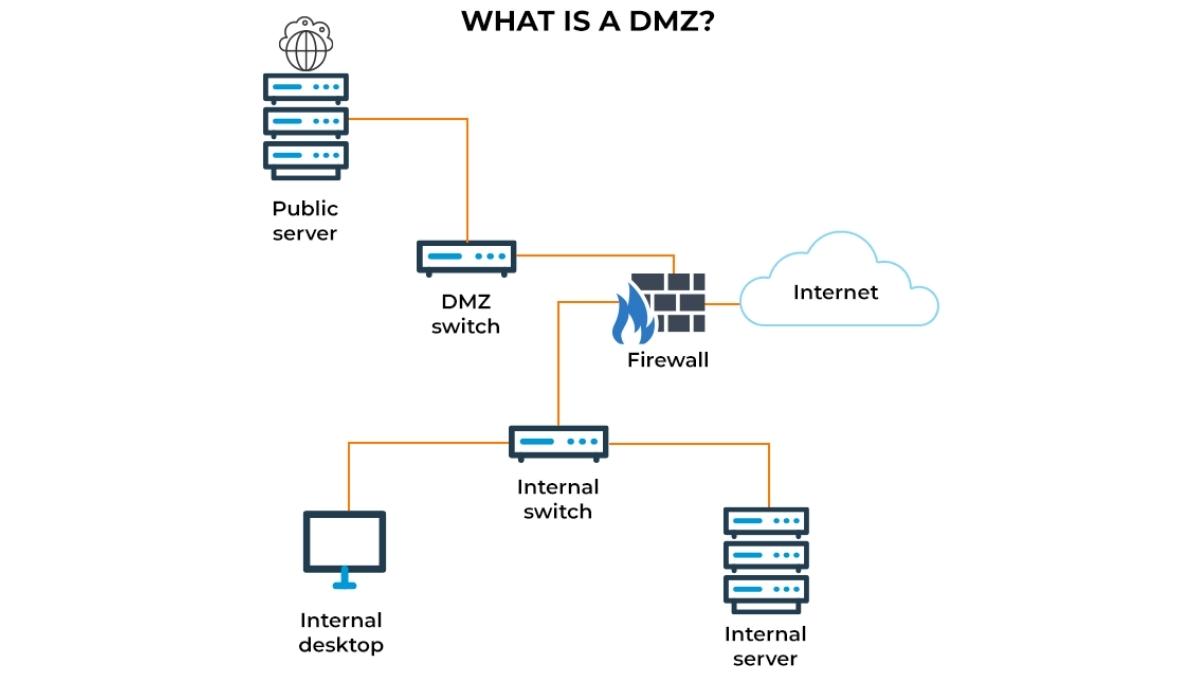
 Wifi Aruba
Wifi Aruba Load Balancing FortiADC
Load Balancing FortiADC  Firewall FortiNAC
Firewall FortiNAC Firewall Fortiweb
Firewall Fortiweb RAM Server
RAM Server HDD Server
HDD Server Phụ kiện Server
Phụ kiện Server Modem Gateway 3G/4G/5G công nghiệp
Modem Gateway 3G/4G/5G công nghiệp Switch công nghiệp
Switch công nghiệp Router 3G/4G/5G công nghiệp
Router 3G/4G/5G công nghiệp LoRaWan
LoRaWan Máy tính công nghiệp
Máy tính công nghiệp Firewall công nghiệp
Firewall công nghiệp Camera giám sát
Camera giám sát Tổng đài - điện thoại IP
Tổng đài - điện thoại IP Hệ thống âm thanh
Hệ thống âm thanh Hệ thống kiểm soát ra vào
Hệ thống kiểm soát ra vào Phụ kiện Teltonika
Phụ kiện Teltonika License
License Module, Phụ kiện quang
Module, Phụ kiện quang Adapter & nguồn PoE
Adapter & nguồn PoETrong thời kỳ chuyển đổi số hiện nay, các doanh nghiệp đã và đang tạo ra nhiều dữ liệu hơn bao giờ hết. Vì vậy, các tổ chức cần phải có khả năng tối đa hóa dung lượng lưu trữ ở mức tối đa song chi phí đầu tư được cân đối hợp lý. Để giải quyết được bài toán trên, tính năng chống trùng lặp dữ liệu đã được ra đời để phát hiện và loại bỏ dữ liệu trùng lặp trước khi doanh nghiệp thực hiện các tác vụ sao lưu. Cùng Việt Tuấn khám phá chi tiết giải pháp tối đa hóa dung lượng lưu trữ với công nghệ chống trùng lặp của Synology trong bài viết ngay sau đây!

Tổng quan về công nghệ chống trùng lặp dữ liệu
Chống trùng lặp dữ liệu là giải pháp tối ưu khả năng lưu trữ vô cùng quan trọng, góp phần vào việc quản lý dữ liệu hiệu quả trong các hệ thống thông tin và cơ sở dữ liệu của doanh nghiệp hiện nay. Công nghệ chống trùng lặp giúp phát hiện và loại bỏ các dữ liệu trùng lặp không cần thiết hoặc không mong muốn trong dữ liệu của một tổ chức.
Điều này dẫn đến việc sử dụng ít dung lượng lưu trữ hơn, đảm bảo rằng doanh nghiệp của bạn có thể sao lưu dữ liệu của mình một cách hiệu quả với thời gian và tốc độ được tối ưu hóa.
Hiện nay, các hãng công nghệ chuyên về các giải pháp lưu trữ có thể tuyên bố rằng giải pháp của họ cung cấp tỷ lệ chống trùng lặp dữ liệu nhất định. Chẳng hạn như một nhà cung cấp có thể tuyên bố rằng giải pháp lưu trữ của họ có tỷ lệ chống trùng lặp cao hơn 20 lần so với những nhà cung cấp khác, vượt qua đối thủ cạnh tranh với tỷ lệ lên tới 200%.
Tuy nhiên, có rất nhiều biến số có thể ảnh hưởng đến tỷ lệ chống trùng lặp dữ liệu thực tế. Bạn đọc hãy cùng tìm hiểu chi tiết về công nghệ chống trùng lặp dữ liệu và cách đánh giá tỷ lệ chống trùng lặp khi lựa chọn giải pháp sao lưu trong các phần nội dung tiếp theo!
Cách tính tỷ lệ trùng lặp dữ liệu
Để loại bỏ dữ liệu trùng lặp một cách hiệu quả, hệ thống máy chủ lưu trữ của bạn phải được trang bị CPU và công nghệ phần mềm cho phép bạn tiết kiệm dung lượng lưu trữ. Khi sử dụng tính năng chống trùng lặp dữ liệu, hệ thống sẽ xác định các khối dữ liệu trước khi lưu trữ.
Mỗi khối dữ liệu sẽ được gán cho một mã nhận dạng duy nhất, trong khi đó dấu vân tay được gán cho các khối được lưu trữ. Sau đó, dấu vân tay của các khối dữ liệu được lưu trữ sẽ được so sánh với các khối dữ liệu mới được ghi.
Nếu phát hiện khối trùng lặp, hệ thống sẽ tạo một chỉ mục trỏ đến vị trí của dữ liệu trùng lặp. Dữ liệu trùng lặp và dư thừa sau đó sẽ được loại bỏ để tối ưu hóa dung lượng lưu trữ cũng như rút ngắn thời gian của tác vụ sao lưu.
Nguy cơ xảy ra các cuộc tấn công ransomware đã và đang tăng lên mỗi ngày. Vì vậy, các doanh nghiệp đa quy mô hiện nay cần thực hiện chiến lược sao lưu và phục hồi dữ liệu hiệu quả để đảm bảo tính toàn vẹn của dữ liệu quan trọng.
>>> Tham khảo thêm các giải pháp phòng chống ransomware tại đây
Các doanh nghiệp trong thời đại 4.0 có xu hướng sao lưu khối lượng lớn dữ liệu thường xuyên. Điều này có thể dẫn đến việc chi phí lưu trữ tăng lên cao. Dữ liệu mới hoặc dữ liệu đã sửa đổi thường chỉ chiếm một phần rất nhỏ trong tổng số dữ liệu được sao lưu.
Đồng nghĩa với việc: Có rất nhiều dữ liệu được sao lưu hàng ngày có chứa dữ liệu trùng lặp hoặc dư thừa. Và tác vụ sao lưu hay khôi phục dữ liệu của các doanh nghiệp hiện nay vẫn chưa thực sự hiệu quả và tối ưu.
Để tính toán 1 cách chính xác tỷ lệ trùng lặp dữ liệu, tổ chức cần tính toán tỷ lệ phần trăm dữ liệu trùng lặp cuối cùng sẽ bị xóa. Mỗi nhà cung cấp giải pháp có xu hướng tính toán tỷ lệ trùng lặp dữ liệu khác nhau. Vì vậy, Việt Tuấn sẽ đưa ra ba giai đoạn tính toán tỷ lệ trùng lặp dữ liệu được Synology áp dụng trong các giải pháp lưu trữ của hãng ngay sau đây. Mỗi giai đoạn tạo ra một giá trị khác nhau:
- Giai đoạn 1 [Bộ dữ liệu gốc]: Tổng dung lượng dữ liệu cần sao lưu trước khi loại bỏ dữ liệu dư thừa.
- Giai đoạn 2 [Truyền dữ liệu sau khi sao chép]: Lượng dữ liệu có thể được truyền đi để lưu trữ trên máy chủ sau khi sao chép dữ liệu.
- Giai đoạn 3 [Dữ liệu được lưu trữ thực tế]: Lượng dữ liệu được lưu trữ trong máy chủ dự phòng.

Khi đo lường hiệu quả của việc loại bỏ trùng lặp dữ liệu, thương hiệu Synology khuyên bạn nên xem xét Giai đoạn 2 [Truyền dữ liệu sau khi loại bỏ trùng lặp] . Nếu bạn xem giá trị được tạo trong Giai đoạn 1 [Tập dữ liệu gốc], điều này có thể gây nhầm lẫn vì cách đo lường này sẽ chứa cả dữ liệu “cũ” và “mới”. Sau đó được chia cho tổng lượng dữ liệu được giữ lại.
Một số nhà cung cấp giải pháp có thể thổi phồng con số này một cách phi thực tế, khiến người dùng do dự: Liệu nhà cung cấp thực sự sử dụng giai đoạn nào để đo lường hiệu quả của việc loại bỏ trùng lặp dữ liệu?
Bạn đọc có thể tham khảo hình minh họa dưới đây, biểu thị 2 kết quả khác nhau sau khi tính toán. Dễ dàng nhận thấy có sự khác biệt lớn giữa hai điều này, qua đó dẫn đến sự nhầm lẫn vì các doanh nghiệp có thể đang hiểu sai tác dụng của việc chống trùng lặp trong việc sao lưu dữ liệu.

Khi xem xét cách các sản phẩm của đối thủ cạnh tranh thực hiện việc chống trùng lặp dữ liệu, Việt Tuấn nhận thấy rằng: Chia tập dữ liệu gốc trước khi sao chép với dung lượng lưu trữ được sử dụng ở đích để có tỷ lệ giảm dữ liệu lên tới 95%.
Đối với công thức của Synology, kích thước của dữ liệu được truyền khi chia cho dung lượng lưu trữ được sử dụng tại địa chỉ lưu trữ đích sẽ cho ra tỷ lệ trùng lặp dữ liệu trung bình, rơi vào từ 40~66%.
Chẳng hạn như: Shiseido Đài Loan đã có thể tăng dung lượng lưu trữ lên 52% bằng cách sử dụng các công nghệ chống trùng lặp dữ liệu đi kèm với các giải pháp sao lưu của Synology. So với các nhà cung cấp dịch vụ sao lưu khác, Synology cung cấp các giải pháp với mức giá thấp hơn, mang tới cơ hội để các doanh nghiệp tiết kiệm chi phí lưu trữ và tối đa hóa dung lượng lưu trữ để có thể bảo vệ nhiều dữ liệu nhất có thể.
Tối đa hóa dung lượng lưu trữ và giảm chi phí của bạn với tính năng chống trùng lặp dữ liệu
Bằng cách chú trọng đến các mặt hạn chế của doanh nghiệp, Synology đã triển khai công nghệ chống trùng lặp dữ liệu để các tổ chức hiện nay có thể giảm thiểu chi phí đầu tư. Đồng thời tối đa hóa dung lượng lưu trữ của mình.
Các công ty có xu hướng sao lưu liên tục trong khi lưu trữ dữ liệu trên hệ thống của mình. Điều này đồng nghĩa với việc: Nếu dữ liệu trùng lặp không bị xóa trước khi dữ liệu mới được ghi vào thì điều này sẽ tạo ra một không gian lưu trữ tạm thời trên thiết bị sao lưu.
Đây là lý do tại sao Synology triển khai tính năng chống trùng lặp nội tuyến khi thực hiện sao lưu. Trước khi bất kỳ dữ liệu mới nào được ghi vào, hệ thống sẽ đồng thời so sánh nội dung của dữ liệu và thực hiện xóa dữ liệu dư thừa, giảm thiểu tối đa dung lượng lưu trữ cần thiết để lưu trữ.
Đồng thời, Synology cũng triển khai công nghệ chống trùng lặp toàn diện ở cấp độ khối, nhắm vào việc loại bỏ các bản sao trùng lặp giữa nhiều nguồn sao lưu. Điều này nhằm đảm bảo rằng không còn dữ liệu trùng lặp khi thực hiện đồng thời nhiều tác vụ sao lưu trong một thư mục.
Điều này giúp doanh nghiệp tiết kiệm dung lượng lưu trữ mà không ảnh hưởng đến hiệu suất sao lưu.
Tham khảo thêm: Hướng dẫn sử dụng Active Backup for Business trên NAS Synology






Tổng kết
Dữ liệu là tài nguyên vô cùng quan trọng, vì vậy các doanh nghiệp cần áp dụng nhiều cách thức để lưu trữ dữ liệu của mình một cách an toàn. Vì vậy, các doanh nghiệp sẽ cần thiết lập chiến lược sao lưu toàn diện, trước khi phát triển và chọn giải pháp sao lưu đáp ứng nhu cầu mở rộng trong tương lai. Qua đó, giảm tổng chi phí sở hữu (TCO) của doanh nghiệp, song hành với hiệu quả sao lưu, khôi phục dữ liệu luôn ở mức cao nhất. Hi vọng rằng bạn đọc đã có những thông tin cần thiết để hiểu rõ hiệu quả của tính năng chống trùng lặp cũng như cách thức áp dụng công nghệ này tại các doanh nghiệp hiện nay. Đừng quên theo dõi những bài viết công nghệ mới nhất trên Viettuans.vn trong thời gian sắp tới!







![[FULL] Tổng hợp tài liệu CCNA tiếng Việt (từ cơ bản tới nâng cao)](https://viettuans.vn/uploads/2023/01/tu-lieu-ccna-tieng-viet.jpg)



















Bài viết hay, rất hữu ích.